
创建标记分类器 |

|

|

|
|
|
创建标记分类器 |
|
|

|
创建标记分类器
|
创建标记分类器 |
|
|
|
|
|
创建标记分类器 |
|
|
|
|
|
||
在这一节中,我们将:
| • | 使用自定义标记创建标记分类器。 |
| • | 创建有自定义列标题的数据网格。 |
| • | 把标记分类器插入到新的数据网格中。 |
现在我们将使用"BShift"和"TShift"自定义标记数据,来在数据网格中定义标记分类器("NEG(阴性)"、"POS(阳性)"以及"WEAK(弱阳性)")。我们将用这些标记分类器来对样本进行分类,最后决定病人血清匹配的结果。首先,我们要插入一个新的三列四行的数据网格,我们将来要把最后的结果放在其中。
| 1. | 如果第3页不是当前页面,请把它选为当前页。 |
| 2. | 请重复插入数据网格一节中的第1步到第7步,只是把数据网格的名称改为"HLA Results"。 |
这时在版面中的第3页会出现一个数据网格。请把这个数据网格移到"HLA cross-match"数据网格下方的空白区。我们下面要为新创建的"HLA Results"数据网格中的各列重命名。
| 3. | 请重复插入数据网格一节中的第8步到第17步,只是把各列分别命名为"Sample"、"B Result"以及"T Result"。 |
我们现在要把关键字标记$SRC插入到"Sample"列中,使用的方法是从"HLA cross-match"数据网格中复制"Smaple"列。以下步骤针对图T15.33。
| 4. | 请点击"HLA cross-match"数据网格中"Sample"一列的第一个单元格,如图中的灰色高亮所示。 |
| 5. | 请从"HLA cross-match"数据网格编辑器窗口选中关键字标记。被选中的关键字显示为白色。 |
| 6. | 请使用键盘上的Ctrl+C来复制所选文本。 |
| 7. | 请点击"HLA Results"数据网格中"Sample"列中的第一个单元格,如图中的光标所示。 |
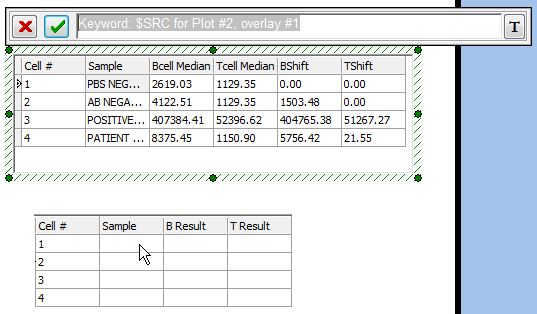
图T15.33 Copying the Keyword Token from the 'HLA cross-match' Data Grid (从'HLA cross-match'数据网格中复制关键字标记)
我们现在要把这个关键字标记粘贴到新建的"HLA Results"数据网格的"Sample"列里。以下步骤都针对图T15.34。
| 8. | 请点击"HLA Results"数据网格里"Sample"列中的第一个单元格,如图中的灰色高亮所示。 |
| 9. | 请使用键盘Ctrl+V把这个关键字标记粘贴到"HLA Results"数据网格的编辑器中。 |
| 10. | 请点击绿色的对勾符号(如图中的光标所示),接受所做的输入。 |
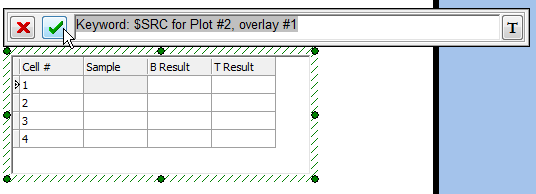
图T15.34 Pasting the Keyword Token into the 'Sample' Column of the 'HLA Results' Data Grid (把关键字标记粘贴到'HLA Results'数据网格里的'Sample'列中)
我们现在将用复制和粘贴来填充Sample列中剩下的单元格。
| 11. | 请为数据网格中"Sample"列里的第二、第三以及第四个单元格重复第4步到第10步,直到网格中的"Sample"列都被填充好,如图T15.35所示。 |
这些都完成后,HLA Results数据网格应该看起来如图15.35所示。
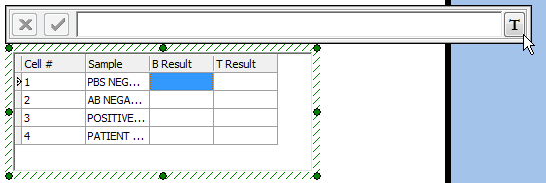
图T15.35 New Data Grid with 'Sample', 'B Result', and T Result' Columns (新的数据网格中的'Sample'、'B Result'以及'T Result'列)
我们现在将开始定义标记分类器,以对所有样本结果进行分类。要想更多地了解如何创建标记分类器,请参见使用文本框和标记教程一节。
| 12. | 请点击"B Result"列中的第一个单元格,如图T15.35中的蓝色高亮所示。 |
| 13. | 请点击自定义数据编辑器窗口中的标记图标,如图T15.35中的光标所示。 |
这时会出现Insert a Token(插入标记)对话框,如前面的图T15.11所示。但是这次用户将注意到在Custom(自定义)类别选项下方有新的列项。
| 14. | 请从Insert a Token(插入标记)对话框中选择Statistic Classifier(统计分类器)。 |
| 15. | 请点击Insert(插入)。 |
这时会出现Create Statistic Classifier(创建统计分类器)下的Classification(分类规则)对话框,如图T15.36所示。这里我们将定义统计分类器,把我们的结果分类为"NEG(阴性)"、"WEAK(弱阳性)"或"POS(阳性)"。但首先我们需要告诉分类器我们想对什么进行分类。
| 16. | 请点击"Enter a value to classify:(输入一个要进行分类的值:)"文本字段旁边的标记图标,如图T15.36中的光标所示。 |
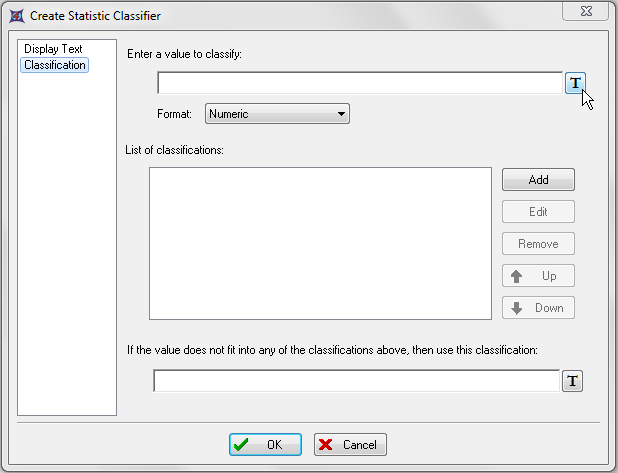
图T15.36 Create Statistic Classifier Dialog -- Classification Category (创建统计分类器对话框 -- 分类选项)
这时会出现Insert a Token(插入标记)对话框,如图T15.37所示。在此我们将为我们的标记分类器选择自定义标记。
| 17. | 请从Insert a Token(插入标记)对话框上的Custom(自定义)列表选项中选择BShift PBS,如图T15.37中的蓝色高亮所示。 |
| 18. | 请点击Insert(插入)。 |
.png)
图T15.37 Insert a Token Dialog with Custom Tokens to Classify (插入标记对话框上用来分类的自定义标记)
这时会再次出现Create Statistic Classifier(创建统计分类器)对话框中的Classification(分类规则)类别选项。但现在"Enter a value to classify:(输入一个要进行分类的值:)"字段已经列出了自定义标记"BShift PBS",如图T15.38所示。下面我们就为分类器输入一个具体的分类规则列表。
| 19. | 请点击Add(添加)按钮,如图T15.38中的光标和蓝色高亮所示。 |
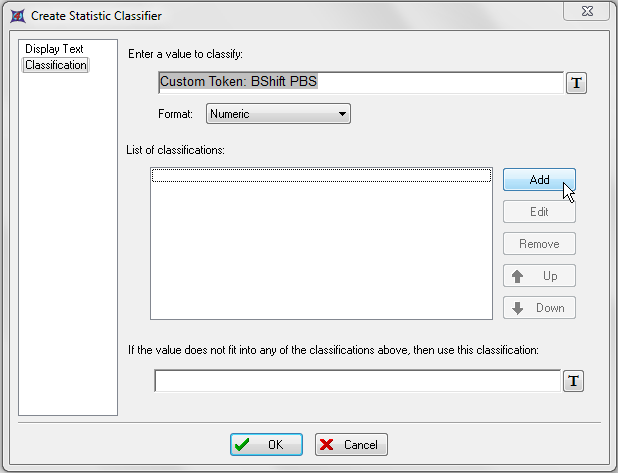
图T15.38 Adding the List of Classifiers in the Create Statistic Classifier Dialog (把分类器列表添加到创建统计分类器对话框中)
这时会出现Edit Classification(编辑分类规则)对话框。以下各步都是针对图T15.39。
| 20. | 请在Classify the token as(把标记归类为)文本字段输入"NEG"。 |
| 21. | 请在if its value is between(如果标记的值在...和...之间)文本字段输入"0"。 |
| 22. | 请在and(和)文本字段里输入"19999"。 |
| 23. | 请点击OK。 |
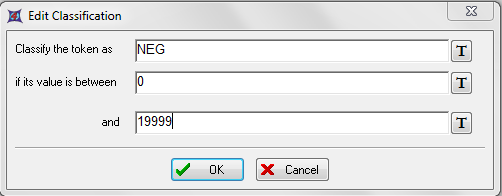
图T15.39 Edit Classification Dialog (编辑分类规则对话框)
这时又会出现Edit Statistic Classifier(编辑统计分类器)下的Classification(分类规则)类别选项对话框。但现在的List of classifications:(分类规则列表)字段已经有"NEG"分类规则列在那里了。我们现在就已经把"BShift"自定义标记的"NEG"分类规则定义为在0到19,999之间。这就是说,如果样本中B细胞的MESF FITC荧光中间值在减去PBS NEGATIVE CONTROL之后小于20,000,那么该样本就被分到阴性或"NEG"一类。
现在让我们来继续定义其它的两个分类"WEAK"和"POS"。
| 24. | 请点击Add(添加)按钮,如图T15.38中的光标和蓝色高亮所示。 |
| 25. | 请在Create Classification(创建分类规则)对话框中的Classify the token as(把标记归类为)文本字段输入"WEAK"。 |
| 26. | 请在if its value is between(如果标记的值在...和...之间)文本字段输入"20000"。 |
| 27. | 请在and(和)文本字段中输入"49999"。 |
| 28. | 请点击OK。 |
| 29. | 请点击Add(添加)按钮,如图T15.38中的光标和蓝色高亮所示。 |
| 30. | 请在Classify the token as(把标记归类为)文本字段输入"POS"。 |
| 31. | 请在if its value is between(如果标记的值在...和...之间)文本字段输入"50000"。 |
| 32. | 请在and(和)文本字段输入"1200000"。 |
| 33. | 请点击OK。 |
这时Edit Statistic Classifier(编辑统计分类器)对话框看起来应该如图T15.40所示,上面显示了针对"BShift"自定义标记的一个完整的分类器定义。
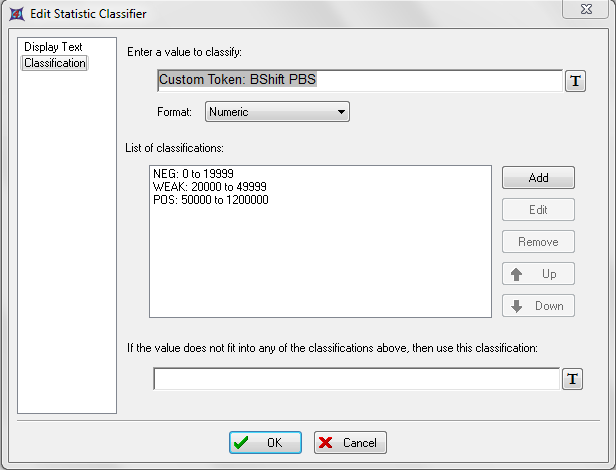
图T15.40 The 'B Result' Token Classifier Definition ('B Result'标记分类器定义)
| 34. | 请点击Edit Statistic Classifier(编辑统计分类器)对话框上的OK,接受这组定义。 |
这时"HLA Results"数据网格也进行了更新,显示出在"B Result"列的第一个单元格中添加的标记分类器,如图T15.41所示。
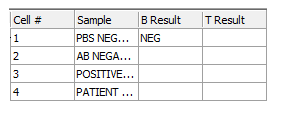
图T15.41 Token Classifier for the 'B Result' Column (针对'B Result'列的标记分类器)
既然我们已经创建了"B Result"列可以使用的分类器,我们便可以把这个分类器复制到这一列中其它的单元格中。这时我们需要做的就是对标记分类器进行编辑,以使用相应的样本数据。
| 35. | 请复制我们在前一步中刚刚创建的"BShift PBS"自定义标记分类器。 |
| 36. | 请把"BShift PBS"自定义标记分类器粘贴到"HLA Results"数据网格中B Result列里的第二个单元格的编辑器中。 |
现在我们需要对标记分类器进行格式化,使得它可以使用AB NEGATIVE HUMAN SERUM样本中的BShift自定义标记。
| 37. | 请在数据网格编辑器"Classification of: 0.00"上双击。 |
这时会出现Edit Statistic Classifier(编辑统计分类器)对话框中的Display Text(显示文本)类别选项。
| 38. | 请选择Edit Statistic Classifier(编辑统计分类器)对话框上的Classification(分类规则)选项(类似于图T15. 40中所示)。 |
我们现在来编辑要被分类的值。
| 39. | 请从Enter a value to classify:(输入一个要进行分类的值:)文本字段中删除"Custom Token: BShift PBS"。 |
| 40. | 请点击Enter a value to classify:(输入一个要进行分类的值:)文本字段旁边的标记图标,如图T15.36中的光标所示。 |
这时会出现Insert a Token(插入标记)对话框,如前面的图T15.37所示。在此我们将选择另外一个自定义标记进行分类。
| 41. | 请从Insert a Token(插入标记)对话框中的Custom(自定义)类别选项中选中BShift NegSerum。 |
| 42. | 请点击Insert(插入)。 |
这时会再次出现Edit Statistic Classifier(编辑统计分类器)对话框中的Classification(分类规则)选项。但是Enter a value to classify:(输入一个要进行分类的值:)文本字段中的自定义标记已经改为"BShift NegSerum"。现在我们将重复上边的这些步骤,把"B Result"列中剩下的单元格填好。
| 43. | 请为"B Result"列中的第三个单元格重复第36步到第42步。但在第41步,请选择BShift PosSerum。 |
| 44. | 请为"B Result"列中的第四个单元格重复第36步到第42步。但在第41步,请选择BShift Patient。 |
这时"HLA Results"数据网格中的"B Result"列就应该完整了,并应该看起来如图T15.42所示。
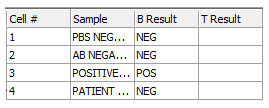
图T15.42 Completed 'B Result' Column (完整填好的'B Result'列)
现在我们将使用"TShift"自定义标记来为"T Result"列定义标记分类器。
| 45. | 请选择"B Result"列中的第一个单元格。 |
| 46. | 请复制标记分类器"Classification of: 0.00"。 |
| 47. | 请选择"T Result"列中的第一个单元格。 |
| 48. | 请把标记分类器粘贴到"T Result"列里第一个单元格的编辑器中。 |
| 49. | 请双击标记分类器"Classification of: 0.00",以对其进行编辑。 |
这时会出现Edit Statistic Classifier(编辑统计分类器)对话框上的Display Text(显示文本)类别选项。
| 50. | 请选择Edit Statistic Classifier(编辑统计分类器)对话框中的Classification(分类规则)列表选项。 |
我们将要修改进行分类的值以及分类规则列表。以下步骤均针对图T15.43。
| 51. | 请选中List of classifications:(分类规则列表:)列表框中的NEG: 0 to 19999 ,如图中的蓝色高亮所示。 |
| 52. | 请点击Edit(编辑)。 |
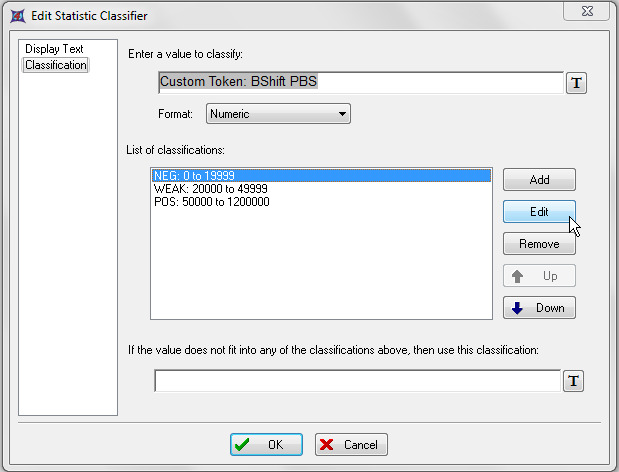
图T15.43 Editing the 'T Result' Token Classifier (编辑'T Result'标记分类器)
这时会出现Edit Classification(编辑分类规则)对话框,如前面的图T15.39所示。在此我们将修改"NEG"的上限。
| 53. | 请在and(和)文本字段中把"19999"改为"1999"。 |
| 54. | 请点击OK。 |
这时再次出现的Edit Statistic Classifier(编辑统计分类器)对话框中的Classification(分类规则)类别选项中的"NEG"被重新定义为从0到1,999之间。我们现在将继续来编辑"WEAK"和"POS"两个分类。
| 55. | 请在List of classifications:(分类规则列表:)列表框中选中WEAK: 20000 to 49999。 |
| 56. | 请点击Edit(编辑)。 |
| 57. | 请把if its value is between(如果标记的值在...和...之间)文本字段中的"20000"改为"2000"。 |
| 58. | 请在and(和)文本字段中把"49999"改为"8000"。 |
| 59. | 请点击OK。 |
| 60. | 请在List of classifications:(分类规则列表:)列表框中选中POS: 50000 to 1200000。 |
| 61. | 请点击Edit(编辑)。 |
| 62. | 请在if its value is between(如果标记的值在...和...之间)文本字段把"49999"改为"8000"。 |
| 63. | 请点击OK。 |
现在我们需要把要进行分类的标记从自定义标记"BShift PBS"改为自定义标记"TShift PBS"。
| 64. | 请删除Enter a value to classify:(输入一个要进行分类的值:)文本字段中的"Custom Token: BShift PBS"。 |
| 65. | 请点击Enter a value to classify:(输入一个要进行分类的值:)文本窗口旁边的标记图标,如图T15.36中的光标所示。 |
这时会出现Insert a Token(插入标记)对话框,如前图T15.37所示。
| 66. | 请从Insert a Token(插入标记)对话框中的Custom(自定义)列表选项中选中TShift PBS。 |
| 67. | 请点击Insert(插入)。 |
这时Edit Statistic Classifier(编辑统计分类器)对话框看起来应该如图T15.44所示,上面显示了针对"TShift PBS"自定义标记的一个完整的分类器定义。
| 68. | 请点击OK。 |
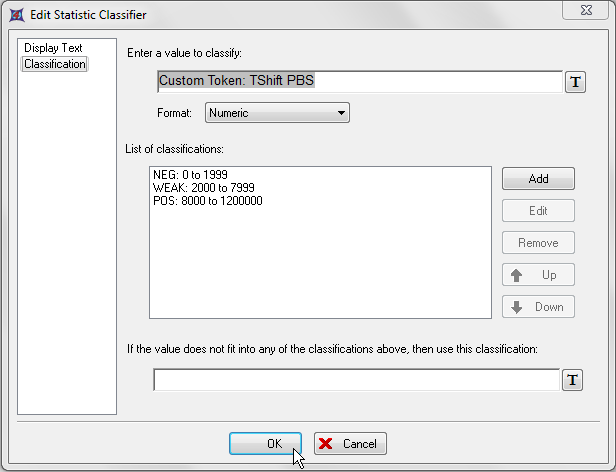
图T15.44 Classifier Definitions of the 'TShift PBS' Custom Token for the 'T Result' Column ('T Result'列里使用的针对'TShift PBS'自定义标记的分类器)
我们现在已经为"TShift PBS"自定义标记创建了分类规则列表。接下来我们要把这个分类器应用到"T Result"列中其它的"TShift"自定义标记上。最简单的方法还是把"T Result"列中的第一个单元格中的"TShift PBS"自定义标记分类器复制到列中的其它单元格中。
| 69. | 请为"T Result"列重复第35步到第44步,只是把"BShift"自定义标记替换为"TShift"自定义标记。 |
当完成所有的复制、粘贴以及编辑标记分类器后,"HLA Results"数据网格将会整个被填满,看起来应该如图T15.45所示。
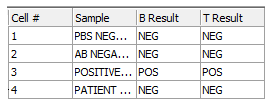
图T15.45 Completed 'HLA Results' Data Grid (填好的'HLA Results'数据网格)
既然我们在数据表中创建了所有的自定义标记以及标记分类器,那么我们就可以保存这个版面,并把它应用到其它数据组上。因为大多数的数据网格都只使用标记,所以数据值会随着绘图的更新而更新。