在大批量筛选实验过程中,实验员经常要对大量(十几万到几千万)的未知实验样本和阳性以及阴性对照做比较。大批量筛选费事也费资源。因此,在开始大批量筛选实验之前用户可以进行一个小规模(或尝试性)的实验,考察一下是否有必要进行大规模筛选。Z-因子用来衡量大范围、高速输出筛选实验的可行性。
FCS Express现在提供在自定义标记中使用Z-函数的功能,让用户可以方便地计算Z-因子。
我们将使用 HighContent_CalculatingZPrime.fey 版面,这个版面中已经嵌入了阳性和阴性的.fcs文件。我们将在这一节中使用标记和自定义标记。要想更多地了解如何使用标记,请查看使用文本框和标记教程 。
1. 请打开 FCS Express Sample Data(FCS样本数据) 文件夹中的版面文件 HighContent_CalculatingZPrime.fey 。
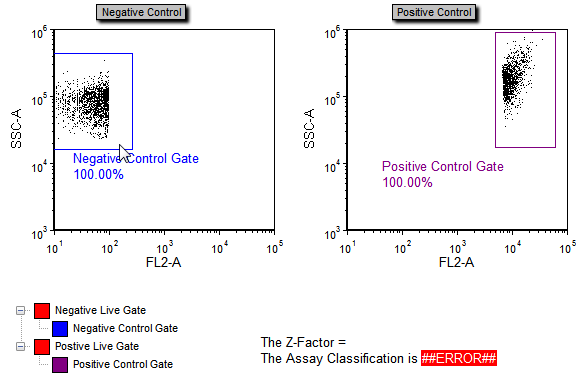
这时版面看起来应该如图T18.35所示。版面左边有一个阴性对照文件,右边有一个阳性对照文件。版面中也有一个文本框,在那里有一个Z-因子的公式以及一个标记分类器。
图T18.35 High Content Calculating Z-Prime Layout (计算Z-函数的高涵量版面)
2. 请选中 View(视图)→Tokens(标记)→Custom Tokens(自定义标记) 命令。
3. 请点击 Custom Tokens(自定义标记) 窗口中的 图标。
4. 请把新的自定义标记命名为"Z Factor(Z因子)"。
5. 请在 Enter the Custom Token formula below(请在下方输入自定义标记公式) 字段中点击。
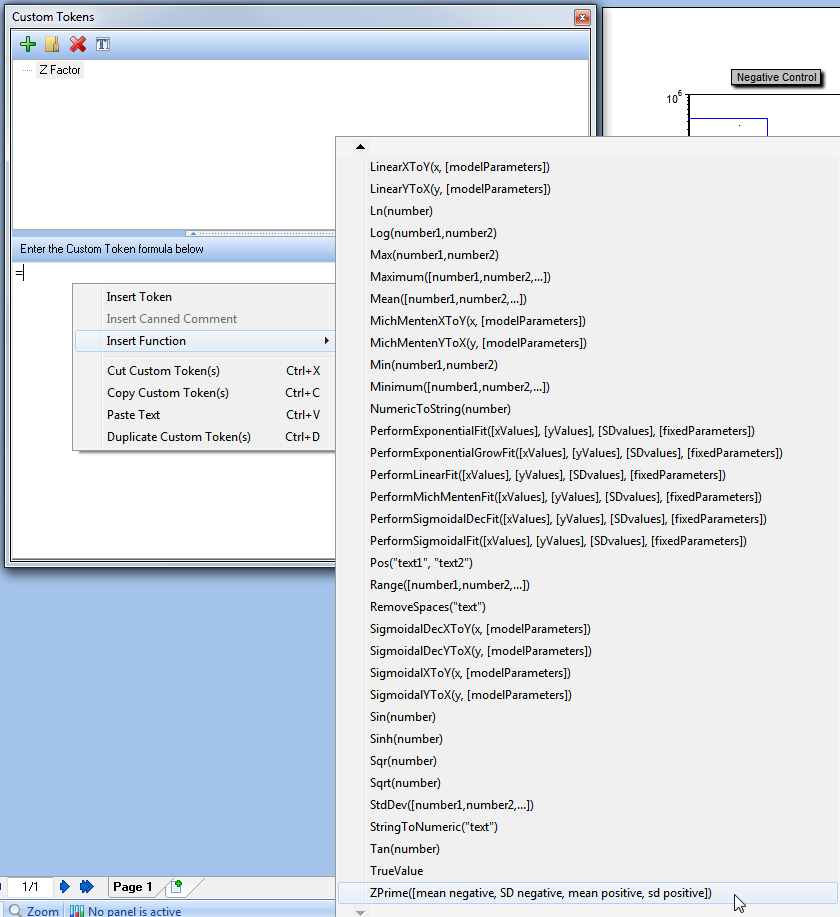
8. 请从弹出菜单上选择 Insert Function(插入函数) 。
9. 请从列表中选择 ZPrime([mean negative, SD negative, mean positive, sd positive]) 函数(图T18.36)。(或者,请按下Z来在列表上选中自动插入的函数)。
图T18.36 Choosing the ZPrime function from the Functions List (从函数列表中选择Z函数)
10. 请在公式字段把 [mean negative 高亮显示(图T18.37)。
11. 请右键点击高亮显示的文本,然后选择 Insert Token(插入标记) 。
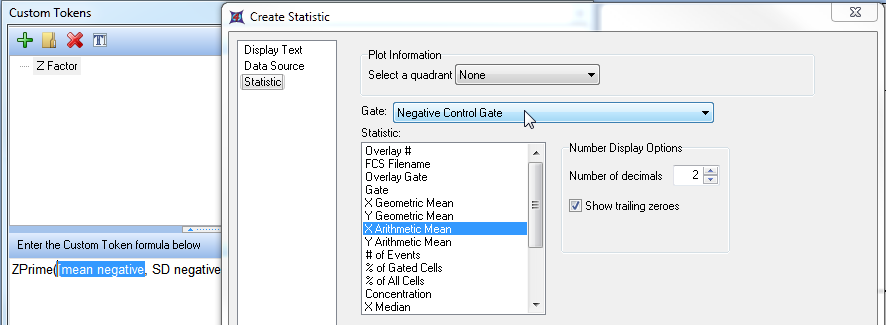
13. 请选择 Negative Control(阴性对照) 绘图作为数据源。
15. 请从下拉列表中选择 Negative Control Gate(阴性对照门) 。
16. 请从 Statistic(统计) 列表框中选择 X Arithmetic Mean(X算术平均值) 。
图T18.37 Replacing Text in a function with a Token (用标记替换函数中的文本)
18. 请在公式字段中高亮选中 SD negative(SD阴性) 。
19. 请右键点击高亮显示的文本,然后选择 Insert Token(插入标记) 。
21. 请选中 Negative Control(阴性对照) 绘图作为数据源。
23. 请从下拉门列表中选择 Negative Control Gate(阴性对照门) 。
24. 请从 Statistic(统计) 列表框中选择 X Standard Deviation(X轴标准偏差) 。
26. 请为" mean positive "和" SD positive] "重复第11步到第25步并使用 Positive Control(阳性对照) 绘图和门。
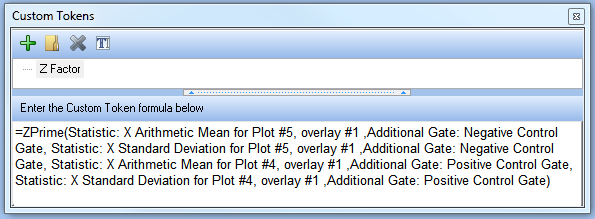
Z因子自定义标记公式现在看起来应该如图T18.38所示,其中的所有文本容器都被相应的标记所替代。
图T18.38 Z Factor Represented by the Z-Prime Function in FCS Express (由FCS Express中的Z-值函数代表的Z因子)
27. 请在版面中文本框里的" The Z-Factor =" 文本之后右键点击。
28. 请从弹出菜单上选择 Insert Token(插入标记) 。
29. 请在 Custom(自定义) 下双击 Z Factor(Z因子) 。
文本框中的Z-因子自定义标记现在显示的值应该为 0.00 。
我们将沿用文献Zhang JH, Chung TD, Oldenburg KR, A Simple Statistical Parameter for Use in Evaluation and Validation of High Throughput Screening Assays. J Biomol Screen . 1999;4(2):67-73中对Z-因子的定义。
• Z-因子为1,非常理想。Z-因子永远不会大于1.0。
• Z-因子在0.5到1.0之间表明这是一个很好的测试。
• Z-因子在0到0.5之间表明测试介于好和不好的边界。
• Z-因子在0以下说明实验中的阳性对照和阴性对照有所交叠,这不太利于对实验样本进行筛检。
在这个版面上已经定义了一个自定义分类器来对Z-因子进行分类。要激活分类器标记:
30. 请在" The Assay Classification is "文本旁边的 ##ERROR## 上右键点击。
31. 请从弹出菜单上选择 Format Token(格式化标记) 。
32. 请选择 Classification(分类规则) 类别选项。
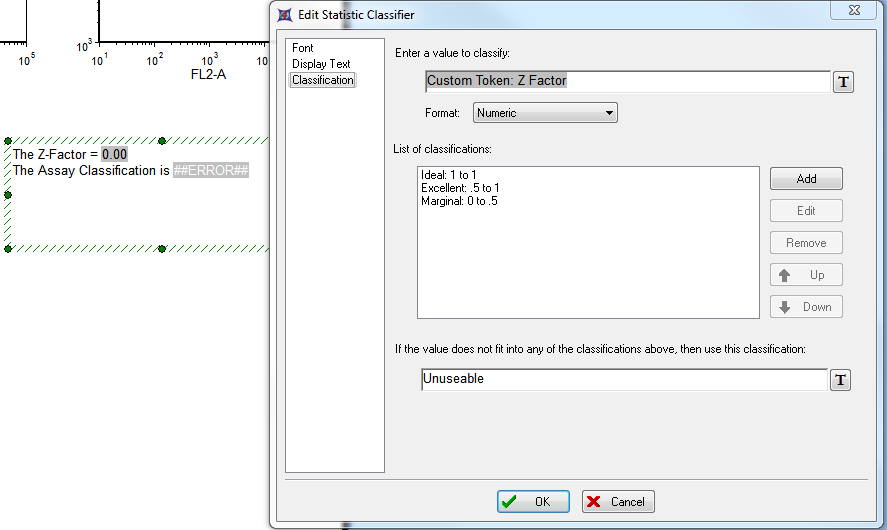
33. 请在 Enter a value to classify(输入要分类的数值) 字段中删除" 4 does not exist "文本。
34. 请点击 Enter a value to classify(输入要分类的数值) 字段中的 图标。
35. 请从 Insert a Token(插入标记) 对话框中双击 Z Factor(Z因子) 。
Edit Statistic Classifier(编辑统计分类器) 对话框应该看起来如图T18.39所示。
图T18.39 Changing the Classification Token to Z Factor (把分类器标记修改为Z因子)
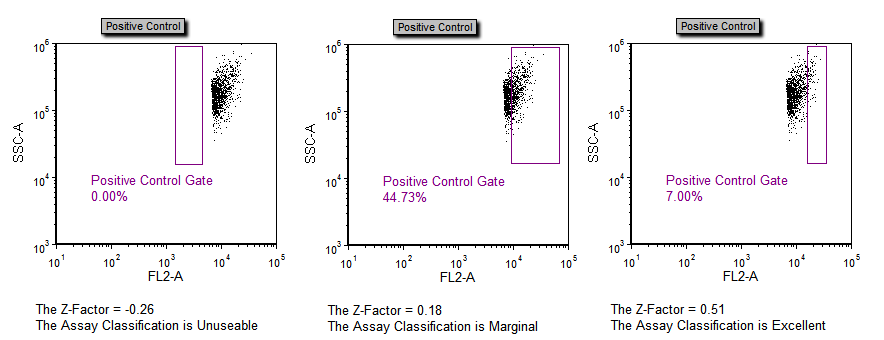
因为该分类器的值为0.00,所以Assay Classification(测试分类器)显示 Marginal(边界的) 。把阳性门调整到试样的不同区域将实时地更新Z因子以及实验分类器。
图T18.40 Gating on the Sample Data Causes the Z Factor and Classification to Update in Real Time (样本数据上门的改变会更新Z因子以及测试分类器)
Help URL:
http://www.yourdomain.com/help/index.html?using_the_z_prime_function.htm